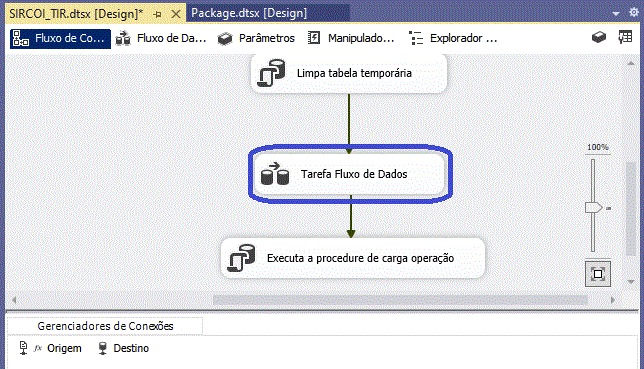
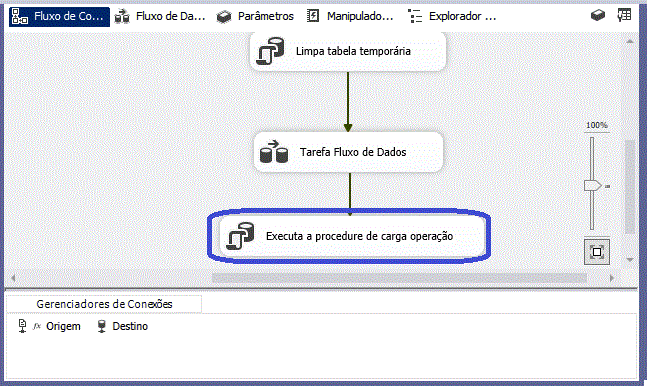
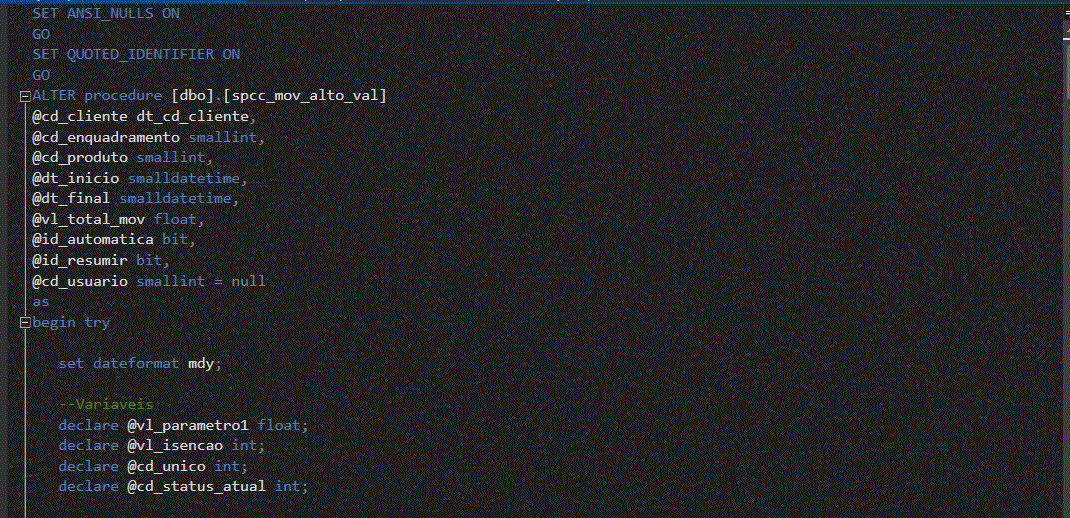
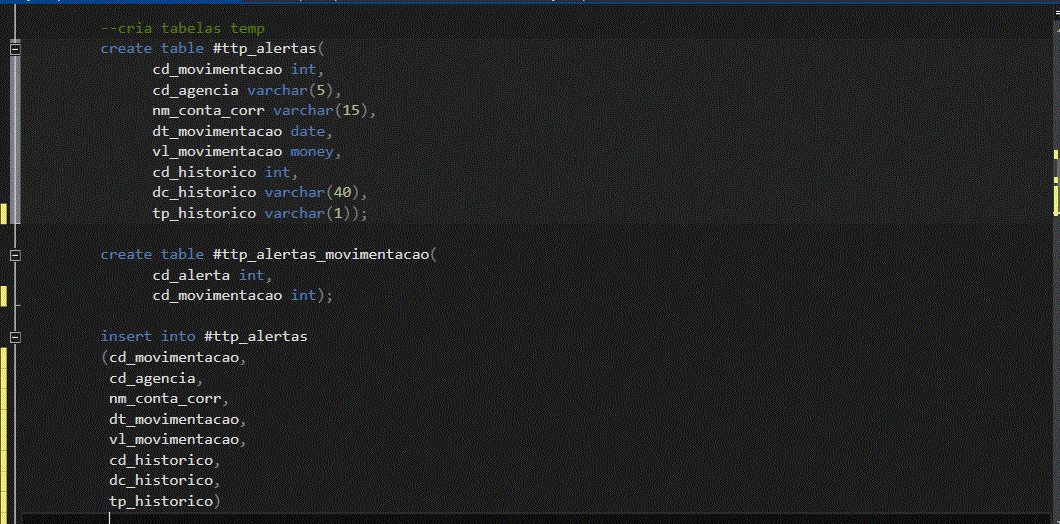
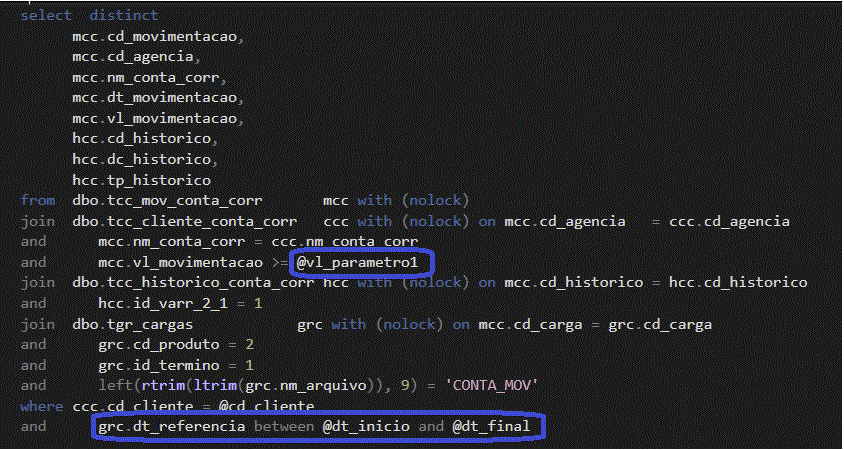
Para a extração das informações vamos utilizar nesse exemplo um arquivo .csv
Esse arquivo contem as informações do cliente e operações realizadas pela instituição em (D-1)(dia menos um, em tradução livre) e é usado para indicar que os dados utilizados em uma determinada análise ou processamento são referentes ao dia anterior ao dia atual.
Exemplo de Arquivo: